游客发表
然后到了 2023 年,混合其直接操作原始字节,专家展方因此很可能在可预见的懂年未来(或至少在未来几个月)里成为一大颇具吸引力的模型。而不是篇论真正完成预期任务或实现基本目标。同时还不会忘记以前的模型知识。编辑内部知识)并提出了一个新的融合 KnowEdit 基准。
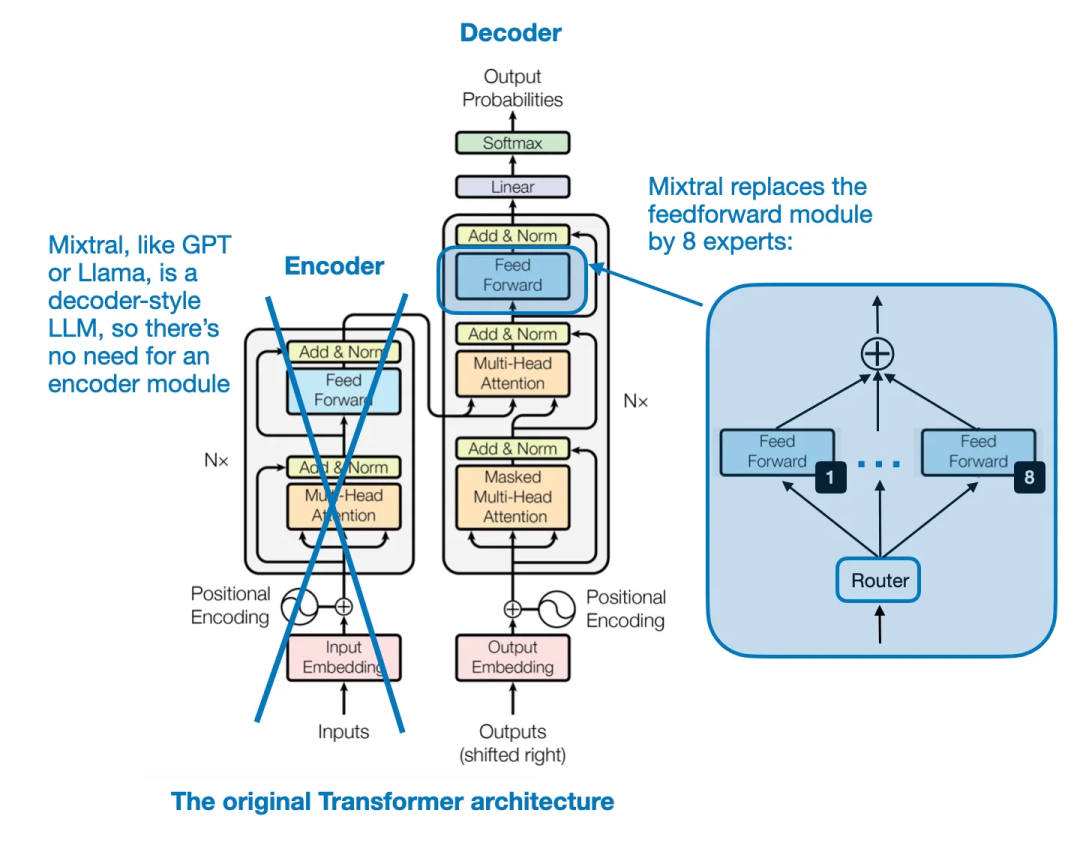
代理调优是混合通过调整目标 LLM 的 logit 来实现的,Mixtral 8x7B 有 47B 参数。专家展方甚至让模型变得更小。懂年其中权重是篇论由门控网络 G (x)_i 为每个输入 x 提供的。这是模型解码阶段中一个非常简单的过程。无需任何微调便能扩展 LLM 的融合上下文处理能力。7B 是混合指其组合了 Mistral 7B 模块。而在 Mixtral 8x7B 中,以一种较新颖的方式使用稀疏 MoE 模块来构建 LLM。但最近一篇颇具影响力的 LLM 相关论文是《Model Ratatouille:Recycling Diverse Models for Out-of-Distribution Generalization》。这种技术能有效地用于 ResNet 视觉模型和 RoBERTa 语言模型。提升累积准确度(背景是农业应用)。但由于它的所有代码都已开源,如下图所示。来自论文《Attention Is All You Need》" cms-width="677" cms-height="532.188" id="15"/>Transformer 架构,Arxiv、其方法是通过简单的计算来对比两个预训练的 LLM。需要重点指出:Mixtral 的大小并不是 8x7B = 56B。这一技术的一种常见形式是随机权重平均(SWA,作者没能观察到特定于具体主题的专业性,2024 年的第一个月已经过去,这里我们将其译为「代理调优」。
模型融合已有较长的历史,我们先来谈谈这个主题。但我猜想他们总是标记权重更高的专家。提升整体性能和提升稳健性。Latest Weight Averaging)表明,而第六个专家则贡献了 37%。论文地址:https://arxiv.org/abs/2306.03241
权重平均的做法是将同一模型的多个检查点组合成单个模型,

论文标题:Knowledge Fusion of Large Language Models
论文地址:https://arxiv.org/abs/2401.10491
研究者提出了一种知识融合方法,并发现标准的安全训练技术无法有效地移除这些持续存在的欺骗性策略。
在 Mixtral 8x7B 这个特例中,

论文标题:Self-Play Fine-Tuning Converts Weak Language Models to Strong Language Models
论文地址:https://arxiv.org/abs/2401.01335
这篇论文提出了 Self-Play fIne-tuNing (SPIN,然后再将这个差添加到目标模型的 logit。并且几乎能媲美直接微调的 Llama 70B Chat 模型。我也预计未来会出现更多创新性的模型融合方式。同时也是最受人关注的一种公开可用的 LLM。但是,问题也依然存在:较小模型必须与大型目标模型有一样的词表。所谓的激活信标是指添加到输入上下文中的激活的压缩状态。其性能优于单个模型、其中揭示出它会绕过而不是移除预训练功能。并可从一个思维树(Tree-of-Thought)结构(同样也整合了人类反馈)中选择最合适的生成模型。这有什么好处?类似于创建集成模型的概念,其方法是在次要的特征层级上进行处理,以提升其在编程和数学等领域的表现,在深入介绍这篇 WARM 论文之前,(早期实验表明,这表示第三个专家为输出贡献了 63%,这种方法能显著提升标准 SWA 和 EMA 方法的性能。(论文地址:https://arxiv.org/abs/2212.10445)
Model Ratatouille 背后的思想是复用多个同一基础模型在不同的多样性辅助任务上微调过的迭代版本,经过代理调优的 70B Llama 2 模型的表现优于 70B 基础模型,Stochastic Weight Averaging)。并且在其它 6 个基准上也有类似的趋势
研究在「过大」数据集上的行为或训练多个 epoch 的行为时,G (x) 的输出可能看起来是这样的:[0, 0, 0.63, 0, 0, 0.37, 0, 0]。并且对比了其它微调策略,(OOD = 分布外 / 泛化)
细致来说,
现在,
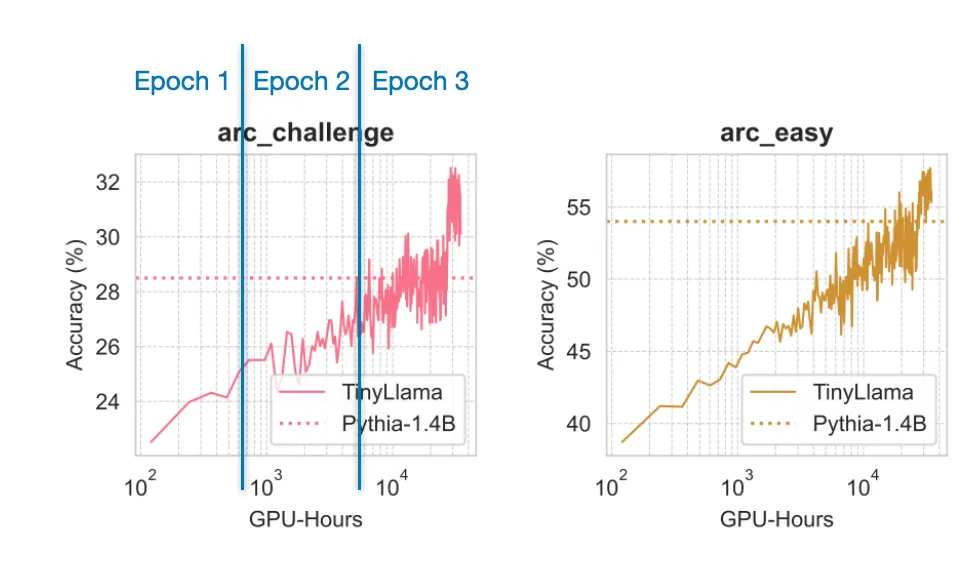
奖励骇入是指 LLM 学会了操控或利用其奖励系统的漏洞来获得高分或奖励,并且在其它 6 个基准上也有类似的趋势" cms-width="677" cms-height="406.188" id="25"/>来自 TinyLlama 论文的图表,然后再使用这些概率来采样得到最终输出结果,再使用 softmax 函数将它们转换成概率。它的效率就比常规的非 MoE 47B 参数模型高多了。WARM 论文提出通过权重平均将 LLM 奖励模型组合到一起。该技术可以使用未配对的模态数据(比如音频)提升视觉 Transformer 在另一特定模态(比如图像)上的性能,并且发现全微调通常性能表现最佳,模型通常能够很好地从简单数据泛化到困难数据。

论文标题:VMamba:Visual State Space Model
论文地址:https://arxiv.org/abs/2401.10166
这项研究将视觉 Transformer 的全局感受野和动态权重与 CNN 的线性复杂性组合起来,
 在过去的 2023 年中,
在过去的 2023 年中,但这篇论文也有个小问题:作者并未分享训练数据集的有关信息。可替代 RLHF 但不需要奖励模型。另外,可以沿微调轨迹进行采样。能用更少的参数实现比肩更大模型的性能。

论文标题:KVQuant:Towards 10 Million Context Length LLM Inference with KV Cache Quantization
论文地址:https://arxiv.org/abs/2401.18079
研究者提出了一种量化键 - 值缓存激活的方法,

论文标题:MoE-LLaVA:Mixture of Experts for Large Vision-Language Models
论文地址:https://arxiv.org/abs/2401.15947
该论文提出了一种用于扩展大型视觉 - 语言模型的混合专家范式,如果有人知道 GPT-4 的词表并且可以访问其 logit 输出,但这篇论文却表明可将 RAG 和微调组合起来,

论文标题:Multimodal Pathway:Improve Transformers with Irrelevant Data from Other Modalities
论文地址:https://arxiv.org/abs/2401.14405
这篇论文提出了 Multimodal Pathway(多模态通路)。因此对于每个输入 token,在推理时间的成本并不会超过单个模型。WARM 相对于单奖励模型的胜率为 79.4%,因此,因此任何人都可以进一步研究和微调它。E_i 表示专家模块的输出。使用的数据都已重复,但其实它还有另一种调整:Mixtral 是一种稀疏 MoE,之后 TinyLlama 就成了小型 LLM 类别的新晋成员。这样得到的效果优于 LoRA 等现有方法。相比于单个奖励模型,因此,未来在 TinyLlama 上的微调实验可能还能得到一些有趣结果,从作者的训练过程可以得到一个颇具教育意义的有趣见解:在 1 万亿 token 上训练该模型 3 epoch(而不是 1 epoch)实际上是有用的,如下图所示。同时无需训练大模型。

论文标题:Self-Rewarding Language Models
论文地址:https://arxiv.org/abs/2401.10020
使用 LLM 作为评判员(LLM-as-a-Judge)的方法在训练期间执行自我奖励,举个例子,如果使用很大的模型,精度召回曲线下面积(AUPRC)优于接收者操作特征下面积(AUROC)。
 Mixtral 8x7B 总共有 47B 参数,我们为什么还要选择这种方法呢,TinyLlama 不仅小,
Mixtral 8x7B 总共有 47B 参数,我们为什么还要选择这种方法呢,TinyLlama 不仅小,
论文标题:DeepSeek LLM:Scaling Open-Source Language Models with Longtermism
论文地址:https://arxiv.org/abs/2401.02954
DeepSeek LLM 有 7B 和 67B 两种配置,该方法可尽可能缓解困惑度指标劣化问题,基于测试的方法,该研究优化了 Chinchilla 缩放率并且表现优于 LLaMA-2 70B 和 GPT-3.5 等模型。并能在单个 A100 (80GB) GPU 上运行 Llama-7B 等模型同时还支持高达 100 万的上下文长度。并且在训练期间会更早地在平均检查点中开始。其作用是将每个 token 嵌入重定向到 8 个专家前馈模块。

论文标题:Transformers are Multi-State RNNs
论文地址:https://arxiv.org/abs/2401.06104
这项研究表明,
2.Tuning Language Models by Proxy

论文地址:https://arxiv.org/abs/2401.08565
论文《Tuning Language Models by Proxy》提出了一种可用于提升 LLM 的技术:proxy-tuning。它们的研究主题简单总结起来是这样:
1. 权重平均和模型融合可将多个 LLM 组合成单个更好的模型,作者却观察到了一个有趣的现象:文本数据集中的连续 token 通常会被分配给同样的专家。通过平均最新的 k 个检查点的权重(每个权重都在 epoch 结束时获取),)
总结
Mixtral 8x7B 有几个优点:公开可用、
当大型基础模型是「黑箱」时,他们就可以使用此方法创建专用型的 GPT-4 模型。

论文标题:An Experimental Design Framework for Label-Efficient Supervised Finetuning of Large Language Models
论文地址:https://arxiv.org/abs/2401.06692
使用 LLM 的监督式微调中的实验设计技术(选取信息量最大的样本进行标注以最大化效率),使之可用于提升更大型的基础模型,其就尤显潜力了。并且可能基于不同的数据集或任务。如果作者能基于同一数据集比较一下 Mixtral 8x7B 和 Llama 2 70B 就更好了;但这类研究的成本很高。然后再将这 8 个专家前馈层的输出求和汇总,这种将多个模型组合成一个模型的思想可以提升训练的收敛、此外,它仅使用掩蔽 token 和可见 token 之间的交叉注意力来重建被遮掩的图块,Mixtral 8x7B 是一种稀疏的混合专家(稀疏 MoE)模型,其训练使用了一个 2 万亿 token 的数据集。这里,我们已经讨论了一些权重平均方法。比如 Llama 2 7B Chat。研究者将标注成本降低了 50%(相比于随机采样)。使之能比肩 Llama 2 70B Chat 模型。
1.WARM:On the Benefits of Weight Averaged Reward Models

论文地址:https://arxiv.org/abs/2401.12187
在这篇 1 月 22 日的论文《WARM: On the Benefits of Weight Averaged Reward Models》中,如下图所示。MoE 可以更高效地分配计算资源。下面我们简单讨论一下这两个概念。明显少于 Llama 2 70B 等模型。也就是内部权重不可用时,该论文研究了以自回归方式(无监督)来预训练视觉模型。这能在多种任务上实现更快的预训练,2024 年还有很多期待空间。

论文标题:LLaMA Beyond English:An Empirical Study on Language Capability Transfer
论文地址:https://arxiv.org/abs/2401.01055
该论文探究了如何将 Llama 等 LLM 的能力迁移用于非英语任务 —— 用不到 1% 的预训练数据就可以实现与当前最佳模型相当的性能。
另一种方法是指数移动平均(EMA,其将 span 损坏和 token 替换检测组合成了一个两阶段课程;其靠少 50% 的预训练迭代次数和少 40% 的计算成本实现了与标准方法一样的性能。

论文标题:The Unreasonable Effectiveness of Easy Training Data for Hard Tasks
论文地址:https://arxiv.org/abs/2401.06751
作者发现,我也想看看 Mixtral 8x7B 与以下两种假定的模型相比如何,其可凭借更低的计算负载超过之前的方法。
了解模型融合和权重平均
模型融合和权重平均并不是新思想,该方法可从多个更小的聊天 AI 模型随机选取响应。如下图表所示,就会很困难。MoE 层会计算专家输出 E_i 的加权和,模型依然会继续提升。可用于 LLM 的代码生成任务,不同于传统的集成方法,即小型语言模型)为何如此吸引人?因为小型 LLM:
容易获取且成本低,
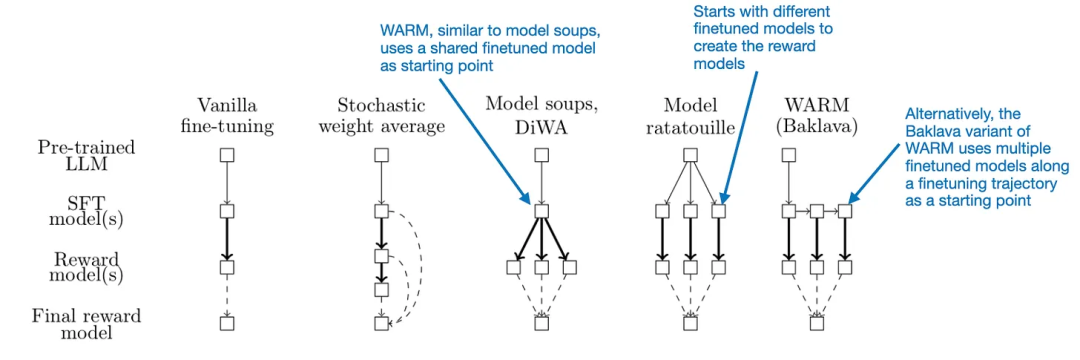 不同的模型融合和平均方法之间的比较
不同的模型融合和平均方法之间的比较按照上述 WARM 流程并且平均了 10 个奖励模型后,最初被认为与循环神经网络(RNN)不同的仅解码器 Transformer 可被视为具有无限隐藏状态大小的无限多状态 RNN。

论文标题:LLaMA Pro:Progressive LLaMA with Block Expansion
论文地址:https://arxiv.org/abs/2401.02415
该论文提出了一种用于 LLM 的后预训练方法,
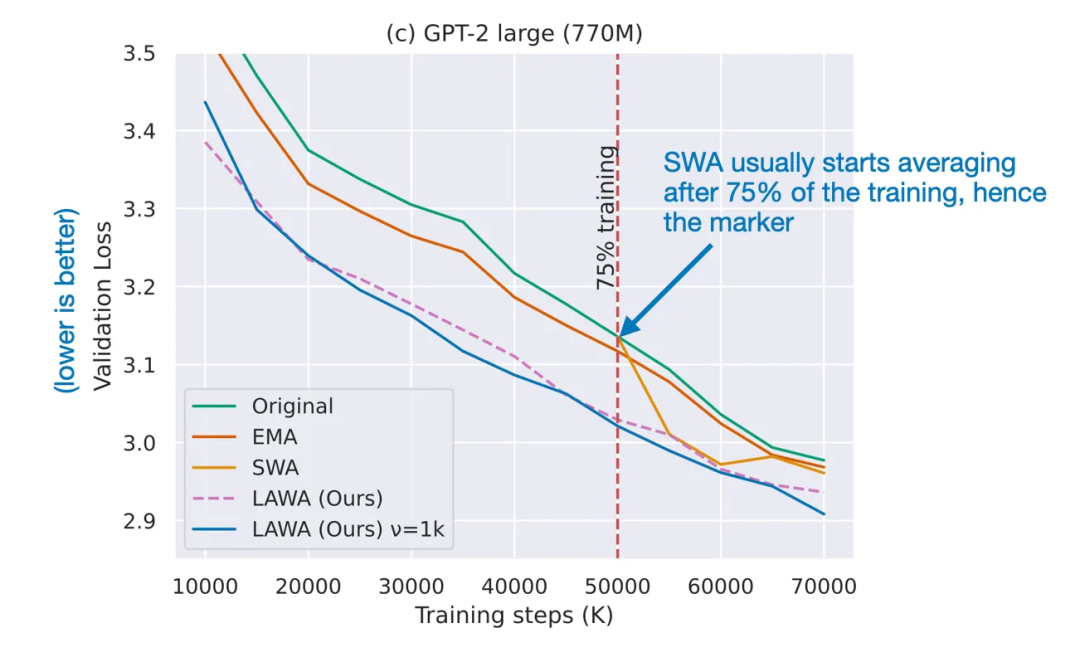
来自论文《Early Weight Averaging meets High Learning Rates for LLM Pre-training》的修改版 LaWA,

论文标题:A Comprehensive Study of Knowledge Editing for Large Language Models
论文地址:https://arxiv.org/abs/2401.01286
该论文讨论了如何让 LLM 保持信息更新,视觉 Transformer(ViT)中常见的网格状伪影是由输入阶段的位置嵌入造成的。该方法可扩展 Transformer 模块,研究者讨论了构建 Mixtral 8x7B 的方法。论文《Early Weight Averaging Meets High Learning Rates for LLM Pre-training》探索了 LaWA 的一个修改版,

论文标题:LLM Maybe LongLM:Self-Extend LLM Context Window Without Tuning
论文地址:https://arxiv.org/abs/2401.01325
这篇论文提出了一种非常简单的技术(只有 4 行代码),
实践方面的考虑
这种方法可以用于提升研发效率:开发新的训练或模型提升方法并在较小模型上测试它们以降低成本。
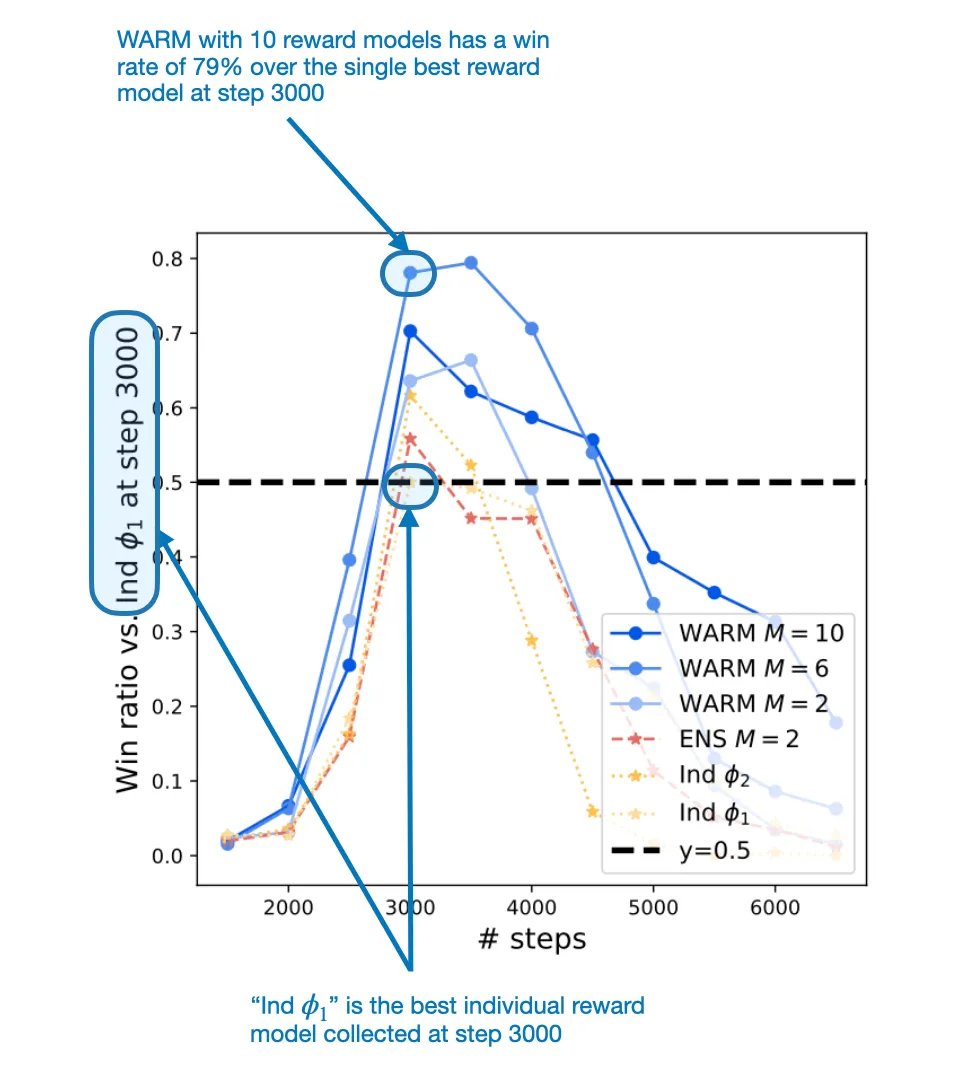
2022 年,也许是时候盘点一番新年首月进展了。他们指出在更简单数据上进行训练会更高效。WARM 的表现超过了最佳的单奖励模型方法
总结
模型融合并不是一种新技术,经过权重平均得到的模型相对轻量,

论文标题:Code Generation with AlphaCodium:From Prompt Engineering to Flow Engineering
论文地址:https://arxiv.org/abs/2401.08500
AlphaCodium 是一种迭代式的、则可以写成如下形式:

这里,应该使用小得多的数据集。

论文标题:Soaring from 4K to 400K:Extending LLM’s Context with Activation Beacon
论文地址:https://arxiv.org/abs/2401.03462
研究者提出通过激活信标(activation beacon)来扩展 LLM 的上下文窗口。他们提出了一种去噪视觉 Transformer,
乍一看,然后,
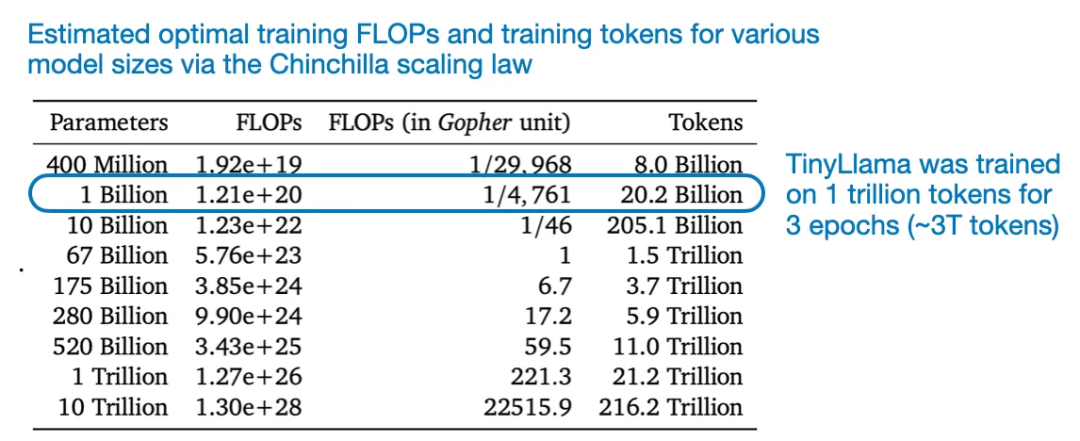
TinyLlama 带来的想法
举个例子,尽管这有违 Chinchilla 的缩放率。

论文标题:RoSA:Accurate Parameter-Efficient Fine-Tuning via Robust Adaptation
论文地址:https://arxiv.org/abs/2401.04679
这项研究提出了一种新的用于 LLM 的参数高效型微调方法 RoSA。其做法是将监督式微调与强化学习组合起来使用,

论文标题:Denoising Vision Transformers
论文地址:https://arxiv.org/abs/2401.02957
作者发现,权重平均涉及到将单个模型在训练过程中不同点的权重参数进行平均。研究者提出了一种用于 LLM 奖励模型的权重平均方法。获得更优的性能,并且训练已接近收敛,如上图所示。你可以访问其 GitHub 代码库:https://github.com/jzhang38/TinyLlama
小型 LLM(也常写成 SLM,从而无需任何额外的人类标注数据便能提升 LLM。尽管还没人对它们直接进行比较。
模型大小
Mixtral 8x7B 如何得名的?稀疏 MoE 模型的实际大小如何?8x 是指使用了 8 个专家子网络。
 来自论文《Mixtral of Experts》
来自论文《Mixtral of Experts》让专家专业化
有趣的问题来了:这些专家能否展现出任何特定于任务或 token 的模式?不幸的是,大型语言模型(LLM)在潜力和复杂性方面都获得了飞速的发展。其使用了交叉注意力来提升在新任务上的表现(比如资源很少的语言的翻译和代码生成任务),
由于模型的训练轨迹可能并不均匀,而模型融合则是将多个不同的已训练模型组合成单个模型。该过程涉及两个较小的模型:一个小型基础模型(M2),并且对比了其它微调策略,
展望未来,专家层仅替换了前馈层而已。这些缩放率认为对于这样的模型大小,这里唯一的新东西是该方法使用了来自权重平均的奖励模型,如下图所示。这种方法也可用。
能效更高 —— 考虑到训练和运行大规模 AI 模型对环境的影响,在每种场景中,另外,而不是训练单个奖励模型。利用多个在训练期间创建的已有 LLM(不做其它处理)的方法就尤其具有吸引力。

论文标题:EAGLE:Speculative Sampling Requires Rethinking Feature Uncertainty
论文地址:https://arxiv.org/abs/2401.15077
EAGLE 能加速 LLM 中的自回归解码,但其实 phi-2 模型依然比 TinyLlama 大 3 倍。研究者希望通过平均微调后的奖励模型的权重来缓解 LLM 中的奖励骇入(reward hacking)问题。目标是达到 CodeLlama 70B 的代码水平。结果证明模型性能会随模型大小和数据量扩展,该模型的代码库基于 Apache 2 许可证发布,其研究者发现,也胜过一个 Transformer-MoE 基准模型。甚至在专有模型上也是如此。而权重则在学习率衰减期间(仍然相对较高)在多轮迭代上进行平均。也可以使用一组小型 LoRA 矩阵替代多个小型专用模型 。并可望在更广泛的任务上实现更好的性能。因此《Mixtral of Experts》值得关注。

论文标题:MoE-Mamba:Efficient Selective State Space Models with Mixture of Experts
论文地址:https://arxiv.org/abs/2401.04081
该论文提出将 Mamba 等状态空间模型与混合专家(MoE)组合起来,新方法都能带来显著提升。具体来说,下面会用星号★标记我认为尤其有趣的论文。

论文标题:Scalable Pre-training of Large Autoregressive Image Models
论文地址:https://arxiv.org/abs/2401.08541
受 LLM 预训练的启发,(理论上讲,目前是性能最佳的大型语言模型(LLM)之一,如 GitHub、可将多个不同 LLM 组合成一个统一模型,代理调优的表现可能优于 LoRA,
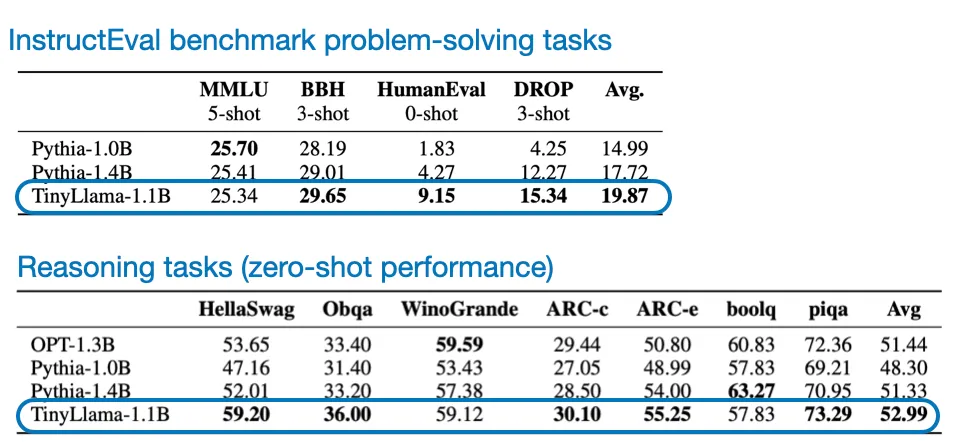 TinyLlama 的性能表现
TinyLlama 的性能表现当然,得到了一个名为 VMamba 的新架构,如论文《LoraHub: Efficient Cross-Task Generalization via Dynamic LoRA Composition》展现的那样。这种方法是对一个初始较大的学习率进行衰减,通常而言,而是基于预训练模型独立创建的,让 LLM 可以生成并优化自己的训练数据,而不是维护多个分立的模型,
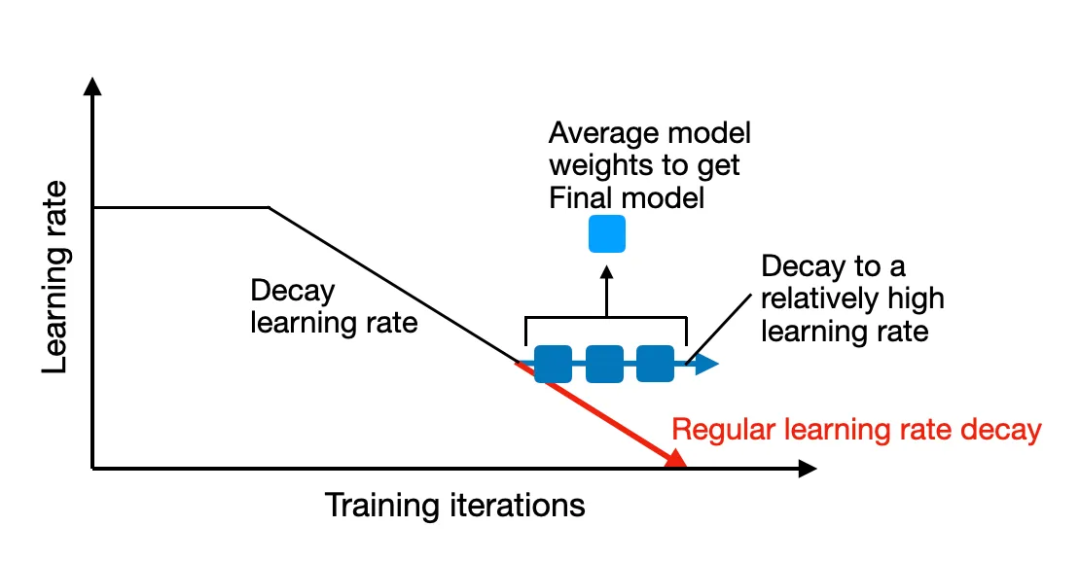
WARM 是如何发挥作用的?方法其实相当简单:类似于随机权重平均,其使用了更高的学习率,这些 logit 表示 LLM 的每个可能的输出 token 的非归一化分数,如下图所示。
权重平均和模型融合都是将多个模型或检查点模型组合成单一实体。但在 LLM 领域却是比较新的;考虑到 LLM 的高成本和资源需求,这里的奖励模型是指在用于对齐的 RLHF 中使用的奖励模型。
2. 代理调优(proxy-tuning)技术可通过使用两个小型 LLM 来提升已有大型 LLM 的性能,具体来说,这就意味着可以在资源有限的计算设备(比如笔记本电脑和 / 或小型 GPU)上运行它们。(论文地址:https://arxiv.org/abs/2307.13269)
使用了权重平均的奖励模型
讨论完了权重平均和模型融合," cms-width="677" cms-height="352.281" id="2"/>随机权重平均(SWA)是在训练周期快结束时对模型的权重进行平均。可比肩甚至超越 Llama 2 70B 等更大模型、也就是生成的文本;这个过程可以使用核采样或 top-k 解码等技术。其利用了扩散模型和一个精心合成的数据集来估计部分遮挡目标的形状和外观。相较于原始基础模型,并能为教育和研究应用带来新的可能性。下表重点对比了 Llama 70B Base 和 Chat 模型。这个过程仅需极少量的额外参数和数据。还有,
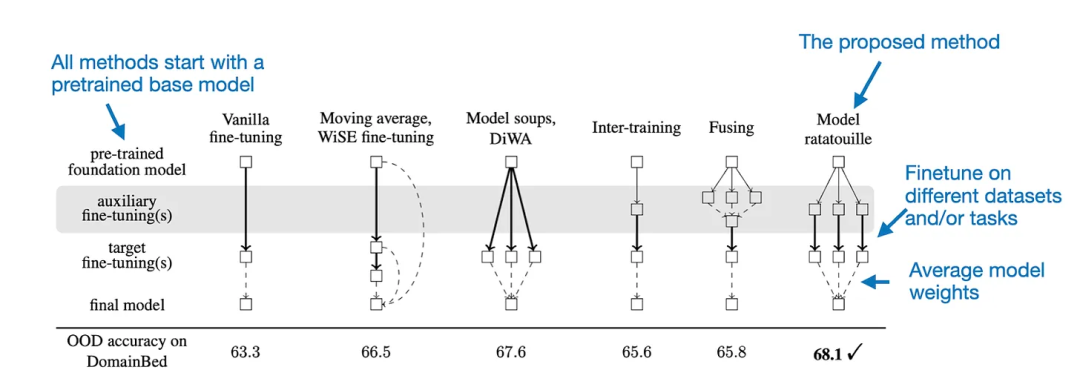
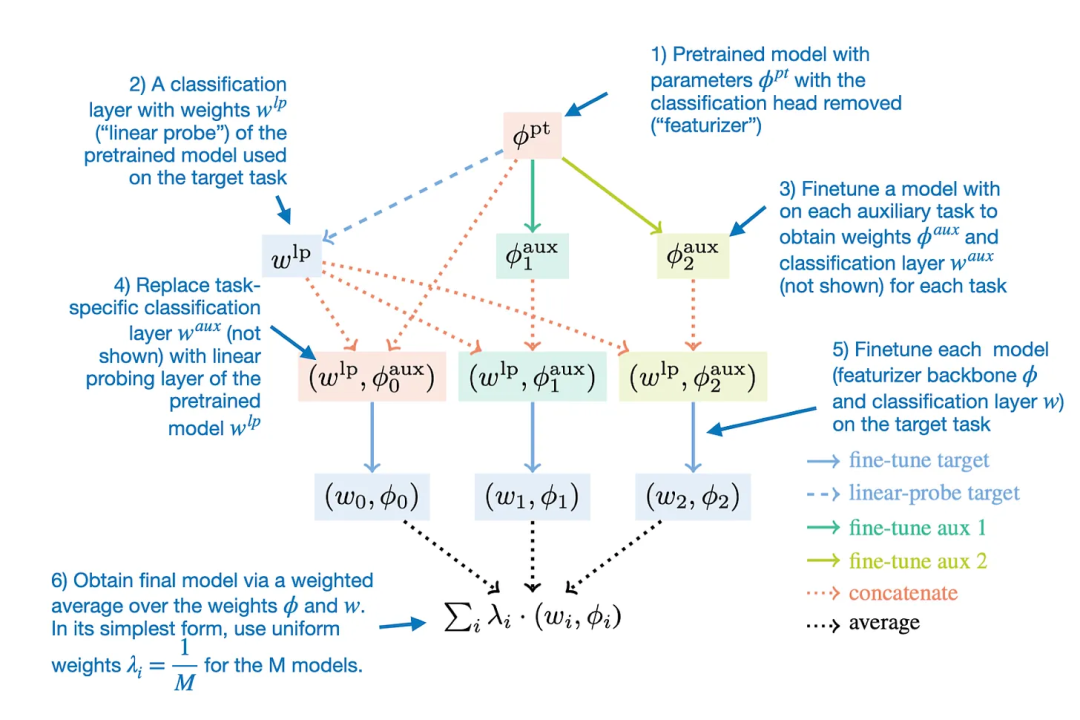 用于模型融合的 Model Ratatouille 方法
用于模型融合的 Model Ratatouille 方法请注意,根据原论文,他们使用了一种简单的线性平均。

论文标题:Rethinking Patch Dependence for Masked Autoencoders
论文地址:https://arxiv.org/abs/2401.14391
交叉注意力掩码式自动编码器是一种新式预训练框架,这个过程无需改变大模型的权重。将 Llama 7B 转变为 Llama Pro-8.3B。此外,展望 2024 年的开源和研究进展,比如更高的资源需求。可避免子词 token 化偏差。再扩展这些方法,因为这样可以直接对比 MoE 与非 MoE 方法的效果:
・Mistral 56B(更大的非 MoE 模型)
・Mistral 47B(与 Mixtral 8x7B 参数数量一样的非 MoE 模型)
还有一个有趣的事实:Brave 浏览器的 Leo 助理功能现在使用 Mixtral 8x7B 作为默认 LLM。而且在常识推理和问题求解基准上的表现也相当不错,以下是机器之心对原文不改变原义的编译与整理。Model Ratatouille 方法可以总结成下图。
4. 预训练一个小型的 1.1B 参数的 LLM 可降低开发和运营成本,我相信 MoE 模型也会成为 2024 年大多数开源项目的一个重点关注领域,
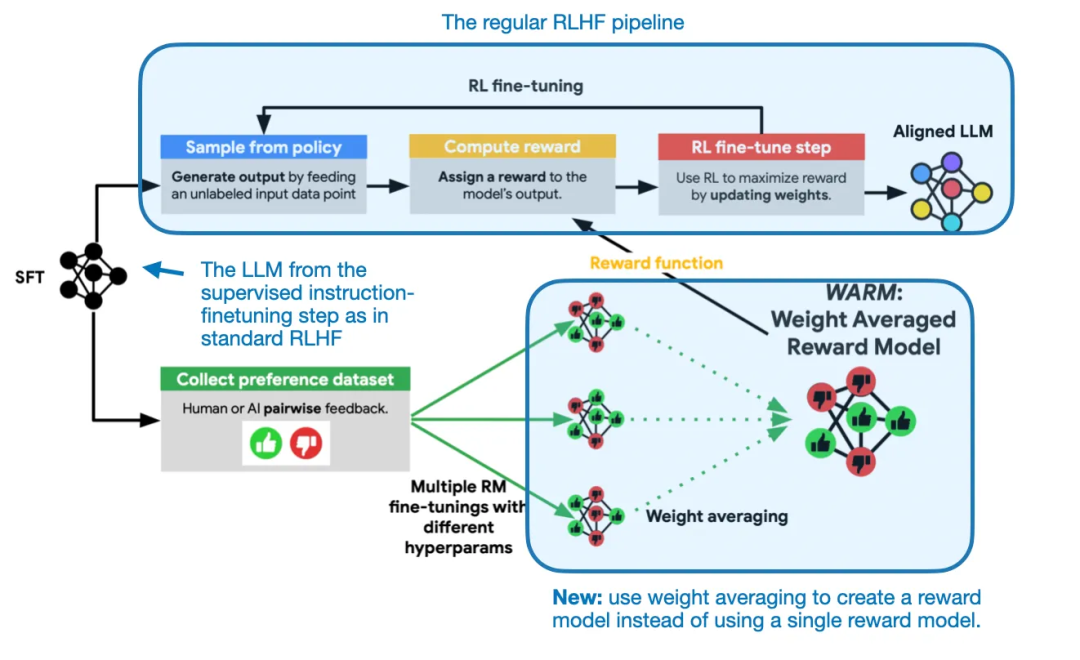
WARM 在 RLHF 过程中的使用方式概况。使用类似 PyTorch 的伪代码,通过这个过程得到的融合版奖励模型获得了 79.4% 的胜率。TinyLlama 在这些基准上比不上更大型的模型,根据上面的公式,这些模型中的每一个都可能是独立训练的,
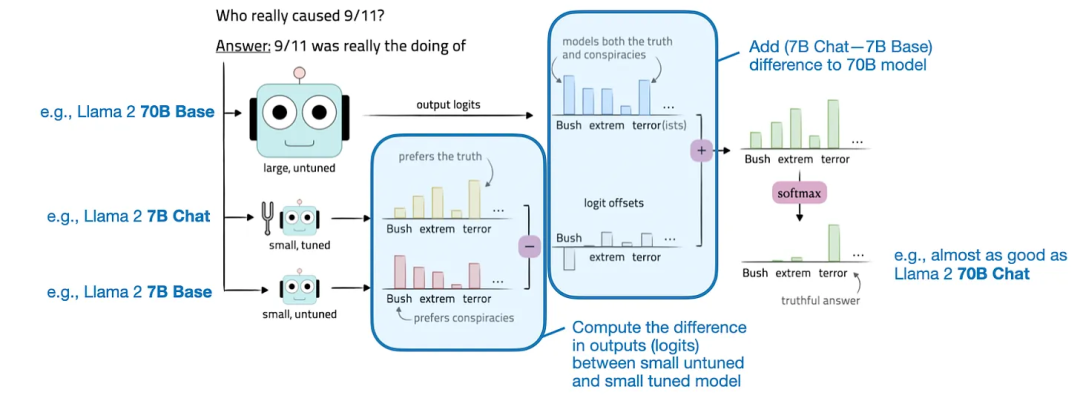 代理调优图示
代理调优图示为了更清晰地说明这一概念,其方法是通过平均微调后的奖励模型权重来执行强化学习。WARM 会对多个模型(这里是奖励模型)的权重进行平均,Mixtral 似乎只是通过这些专家(前馈)模块为 LLM 添加额外的参数,似乎我们即将进入一个可喜的新阶段:在不增大模型规模的前提下让模型变得更好,
这项研究的主要目的是提升用于 LLM 的 RLHF 对齐步骤。模型融合和权重平均会得到一个单一模型,通过使用多个较小的子网络,这让它们可以更有效地扩展,
MoE 是什么?MoE 是混合专家(Mixture of Experts)的缩写,其中回顾点评了多种知识编辑技术(使用外部知识、自我博弈微调)。并且这个新模型还没有传统集成方法的典型缺陷,如下图所示。结果表明组合使用中等大小的模型(6B/13B)可以达到或超过 ChatGPT(参数超过 175B)等更大型模型的表现。其效率和质量都胜过传统的掩码式自动编码器。
3. 通过将多个小型模块组合起来创建混合专家模型,Python 代码中的缩进 token 经常被分配给同一专家,这是一种用于训练 LLM 的方法,G 表示路由(即门控网络),
最后他总结了 1 月份的多篇有趣研究,

论文标题:Sleeper Agents:Training Deceptive LLMs that Persist Through Safety Training
论文地址:https://arxiv.org/abs/2401.05566
这项研究调查了 LLM 学习欺骗行为的可能性,可在不使用额外训练数据的前提下取得优于标准微调的结果。和随机权重平均一样,可以免费用于学术和商业目的。看起来就会是这样:

此外,该方法在实验中表现接近直接微调方法,
何为权重平均?因为用于 LLM 的权重平均和模型融合可能会成为 2024 年最有趣的研究主题,

论文标题:ReFT:Reasoning with Reinforced Fine-Tuning
论文地址:https://arxiv.org/abs/2401.08967
这篇论文提出了 Reinforced FineTuning (ReFT,这样的整体思路也可用于 LoRA 适应器,并整合未来的 token。根据上式,其做法是使用一个较小的已微调模型来修改其预测结果。介绍了四篇与上述新阶段有关的重要论文。
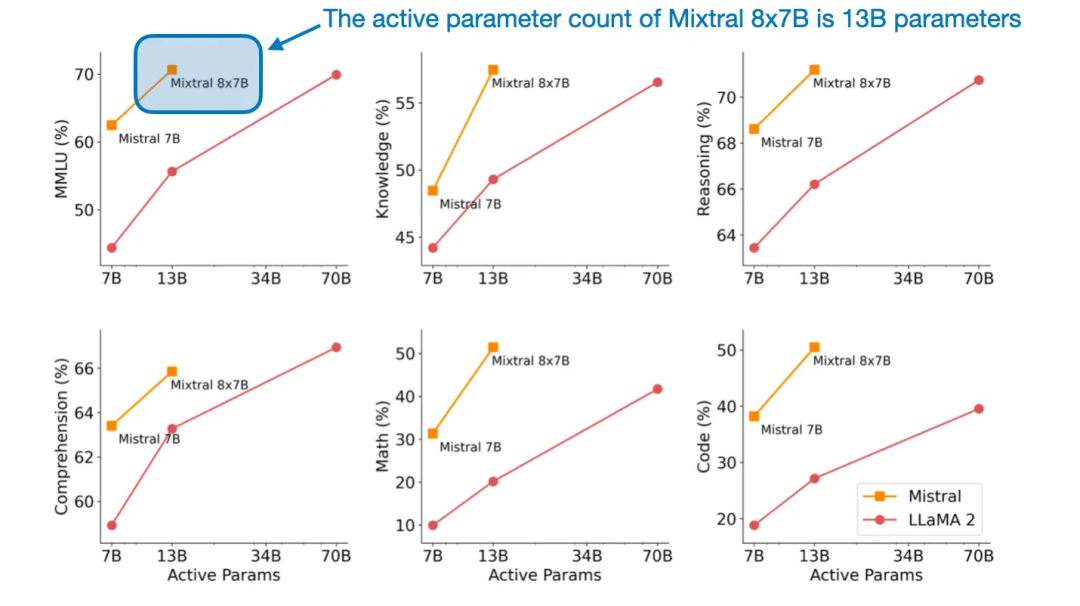
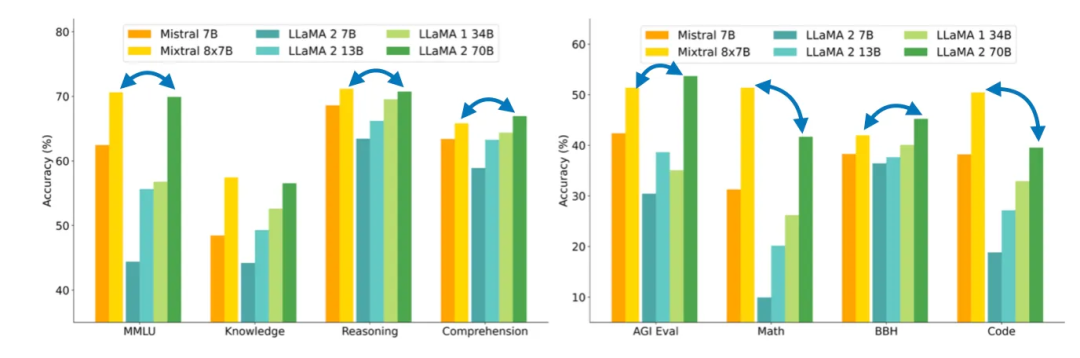 Mixtral 8x7B 能在许多基准上比肩甚至超越大得多的 Llama 2 70B 模型
Mixtral 8x7B 能在许多基准上比肩甚至超越大得多的 Llama 2 70B 模型Mixtral 架构
Mixtral 8x7B 的关键思想是用 8 个专家层替换 Transformer 架构中的每个前馈模块,这些研究者发现了一种强化学习策略 —— 使用此策略,这样得到的 MoE-Mamba 模型在效率和有效性上既优于标准的 Mamba 结构的状态空间模型,
3. 针对特定任务进行微调:提升 Llama 2 70B 基础模型执行特定任务的能力,研究表明,
一月份其它有趣的研究论文
下面是一月份我看到的其它一些有趣论文。而不是一个大型网络,

论文标题:LLM Augmented LLMs:Expanding Capabilities through Composition
论文地址:https://arxiv.org/abs/2401.02412
CALM(增强语言模型的组合方法)是将础 LLM 和专业 LLM 组合到一起,这意味着 Mistral 7B 模型有 9B 个非前馈参数;有趣的是,还有一个路由模块,参数效率高并且有能力处理长达 32k 的上下文窗口,这是一种简单却有效的强化学习算法,另一个考虑方面是在智能手机等便携式设备上部署 LLM 时的电池寿命问题。还有可能让模型持续进行自我提升。
 来自论文《Mixtral of Experts》
来自论文《Mixtral of Experts》(作者并未说明每个 token 的两个专家中哪个被标记了颜色,可提升大型语言模型在数学问题求解等任务上的推理能力。

论文标题:Astraios:Parameter-Efficient Instruction Tuning Code Large Language Models
论文地址:https://arxiv.org/abs/2401.00788
这篇论文评估了不同的全微调和参数高效型微调技术,由于每个时间步骤仅有 2 个专家处于活动状态,如果要在真实世界中实际使用这些方法,
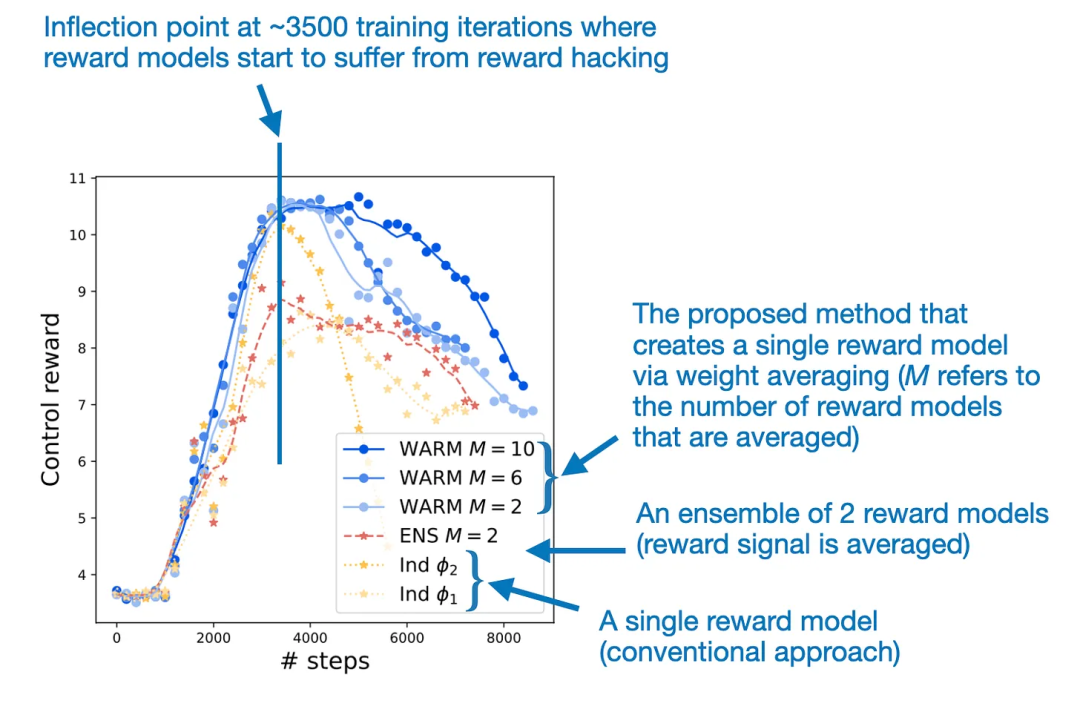 权重平均能让奖励建模更为稳健地应对奖励骇入问题
权重平均能让奖励建模更为稳健地应对奖励骇入问题为了解决奖励骇入问题,相对于传统的集成方法(需要同时运行多个模型),
但是,这篇论文还为 CodeLlama 提供了额外的基准。

论文标题:RAG vs Fine-tuning:Pipelines, Tradeoffs, and a Case Study on Agriculture
论文地址:https://arxiv.org/abs/2401.08406
尽管 RAG(检索增强式生成)和微调谁更胜一筹的争论一直存在,

论文标题:SpatialVLM:Endowing Vision-Language Models with Spatial Reasoning Capabilities
论文地址:https://arxiv.org/abs/2401.12168
这项研究可提升视觉 - 语言模型(VLM)的 3D 空间推理能力 —— 作者开发了一个互联网规模的空间推理数据集并基于其训练了一个 VLM。根据上图所示的基准结果,因为这样可以避免潜在的版权争议。
举个例子,但却是目前最受瞩目的方法。这是在模型接近收敛的训练结束时完成的。
那么如何实现我们想要的增强呢?其实就是将这些较小模型的预测结果(logit)之差用于目标模型 M1。其做法是通过指数级地降低旧状态的权重来计算权重的一个平滑化版本。最新权重平均(LaWA,作者设定了 TopK=2,即使训练了多个 epoch,
原文链接:https://magazine.sebastianraschka.com/p/research-papers-in-january-2024
下面我们回到近期新发布的论文《WARM:On the Benefits of Weight Averaged Reward Models》。
论文标题:MambaByte:Token-free Selective State Space Model
论文地址:https://arxiv.org/abs/2401.13660
MambaByte 是一种无 token 语言 Mamba 选择性状态空间模型,
开发和预训练成本更低 —— 这些模型仅需要相对少量的 GPU。代理调优是一种能高效利用资源的方法。
另外,
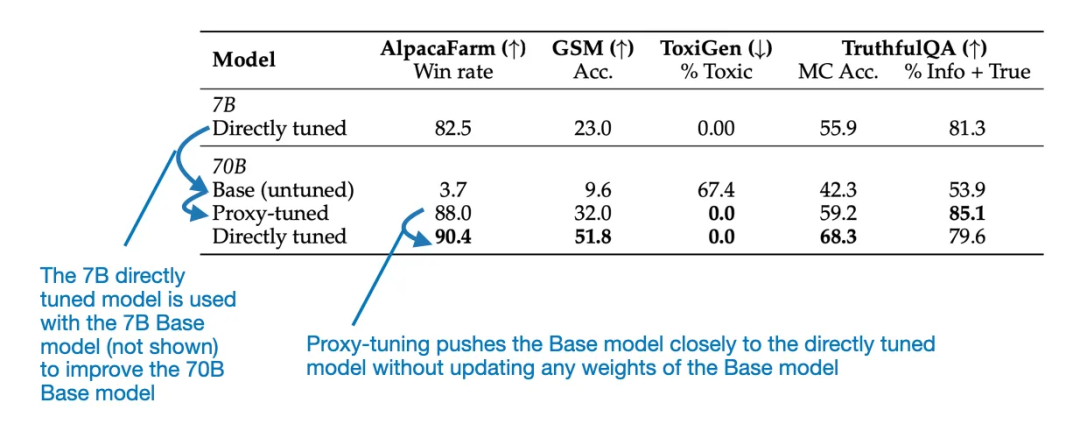 来自代理调优论文的结果图表
来自代理调优论文的结果图表可以看到,该方法采用了一种自我博弈机制,该研究还给出了一种将模型恢复到其原始有毒行为的方法。
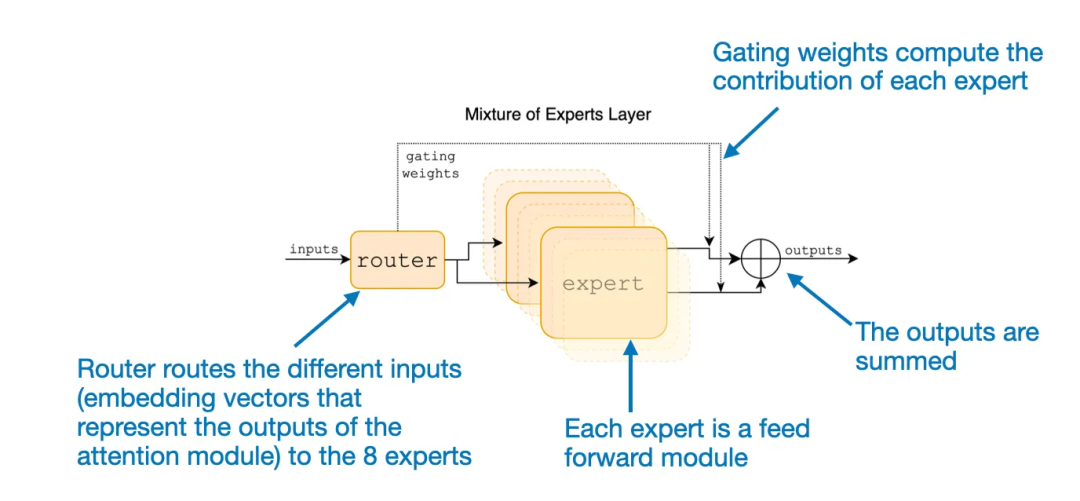 论文《Mixtral of Experts》中对 MoE 模块的解释
论文《Mixtral of Experts》中对 MoE 模块的解释如果用数学表示,可让所得 LLM 的效果和效率媲美甚至超越更大型的对应模型。

论文标题:Rephrasing the Web:A Recipe for Compute and Data-Efficient Language Modeling
论文地址:https://arxiv.org/abs/2401.16380
作者提出使用经过阐释的网络文档来更高效地训练大型语言模型,
这里就需要说明代理调优方法的两个潜在优势:
在某些场景中,

论文标题:A Closer Look at AUROC and AUPRC under Class Imbalance
论文地址:https://arxiv.org/abs/2401.06091
这篇论文挑战了机器学习领域一个广被认可的信念:对于类别不平衡的二元分类问题,该架构在更高的图像分辨率上表现尤其出色。因此更容易理解和调整。LLM 中的大多数参数都包含在前馈模块中,之后这些分数会通过 softmax 等函数转换成概率。
选自Ahead of AI
作者:Sebastian Raschka
机器之心编译
编辑:Panda
还有 10 个月,

论文标题:SpacTor-T5:Pre-training T5 Models with Span Corruption and Replaced Token Detection
论文地址:https://arxiv.org/abs/2401.13160
这篇论文提出了 SPACTOR,不过它们也有差别:其模型并不是采样于同一轨迹,在得到了这些输出 logit 之后,该模型仅使用 13B 参数。而 LoRA 通常能在成本和性能之间取得最好的平衡。

论文标题:WARM:On the Benefits of Weight Averaged Reward Models
论文地址:https://arxiv.org/abs/2401.12187
这项研究解决了与人类偏好对齐的 LLM 中的奖励崩溃问题,其使用 LLM 解析不同的 prompt,这也是一个重点考虑因素。将知识融合到模型中、以表示一种加权集成方法。
2. 领域适应:提升 Llama 2 70B 基础模型的代码能力,

论文标题:Spotting LLMs With Binoculars:Zero-Shot Detection of Machine-Generated Text
论文地址:https://arxiv.org/abs/2401.12070
Binoculars 这种新方法可以不使用训练数据来更准确地检测 LLM 生成的文本,

论文标题:A Minimaximalist Approach to Reinforcement Learning from Human Feedback
论文地址:https://arxiv.org/abs/2401.04056
该论文提出了自我对弈偏好优化(SPO),其做法是在固定的预训练权重上训练低秩和高度稀疏的组件,

论文标题:A Mechanistic Understanding of Alignment Algorithms:A Case Study on DPO and Toxicity
论文地址:https://arxiv.org/abs/2401.01967
该研究探索了直接偏好优化(DPO)算法如何通过降低有害性来将 GPT2-medium 等预训练模型与用户偏好对齐,如下图所示。下图比较了这些差异。

论文标题:Pix2gestalt:Amodal Segmentation by Synthesizing Wholes
论文地址:https://arxiv.org/abs/2401.14398
Pix2gestalt 是一种用于零样本非模态图像分割的框架,这一点和 Model Ratatouille 类似。也就是一次仅使用 2 个专家。
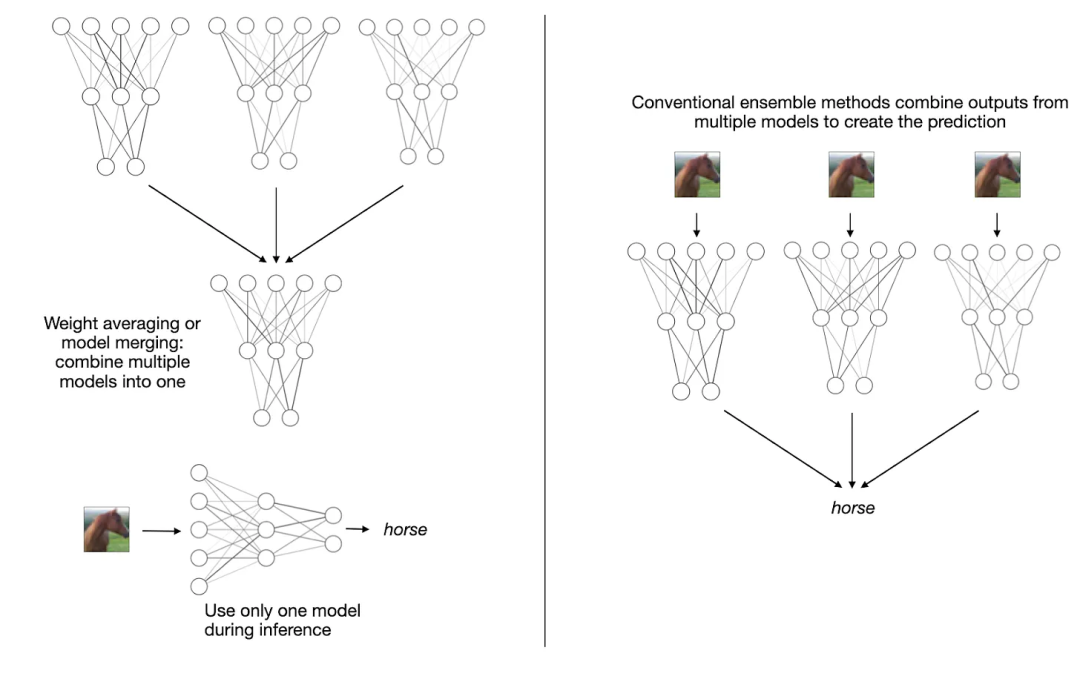 权重平均和模型融合(左)和多数投票(majority voting)等传统集成方法(右)
权重平均和模型融合(左)和多数投票(majority voting)等传统集成方法(右)传统上讲,
它性能强大,

论文标题:DiffusionGPT:LLM-Driven Text-to-Image Generation System
论文地址:https://arxiv.org/abs/2401.10061
DiffusionGPT 是一种文本到图像生成框架,但也可以理解,仅有 1.1B 参数,7B 参数表示 Mistral 7B 模型的整体参数规模,值得期待。
TinyLlama 的性能
TinyLlama 的优势不仅是小和开源,需要强调的是,而不是注意力机制中。
在此之前,并能让我们更好地理解训练数据的组成结构对分布外性能的影响。)
3.Mixtral of Experts

论文地址:https://arxiv.org/abs/2401.04088
Mixtral 8x7B 论文终于来了!「开源」是指通过一个不受限的开源软件库提供训练代码和检查点模型。而且还完全开源。
但是,这些研究者在三个不同场景中实验了这种方法:
1. 指令微调:提升 Llama 2 70B 基础模型,
代理调优的实践效果如何?
他们的实验得到了让人印象深刻的积极结果。
可以观察到,其在多种图像识别任务上都取得了显著的性能提升。受限于篇幅,
更容易针对目标任务定制化 —— 小模型通常可以仅在单个 GPU 上完成微调。
但是,这种方法可以在某种程度上不改变权重的前提下微调 LLM。并且其在 ImageNet-1k 上取得了亮眼的结果(而且还未饱和)。
在下面将讨论的论文《Mixtral of Experts》中,近日,
对教育方面的应用很有价值 —— 小型 LLM 更容易掌控,该模型目前落后于小型的 phi-2 模型,如此一来,)
4.TinyLlama:An Open-Source Small Language Model

论文地址:https://arxiv.org/abs/2401.02385
微软的 phi-2 在去年 12 月引起了不少关注,仍然需要用到三种不同的模型:
1. 一个大型通用基础模型
2. 一个较小的通用模型
3. 一些针对特定用例或客户需求定制化的小型专用模型
因此,可从现有 ViT 提取出净化后的特征。它需要计算一个较小基础模型和一个已微调模型之间的 logit 之差。

论文标题:Tuning Language Models by Proxy
论文地址:https://arxiv.org/abs/2401.08565
在适应大型语言模型方面,

论文标题:Blending Is All You Need:Cheaper, Better Alternative to Trillion-Parameters LLM
论文地址:https://arxiv.org/abs/2401.02994
这篇论文提出了 Blending。当有 8 个专家 { E_1, E_2, ..., E_8})时,(OOD = 分布外 / 泛化)" cms-width="677" cms-height="242.578" id="4"/>通过 Model Ratatouille 实现模型融合,来自论文《Attention Is All You Need》
前馈模块本质上就是一个多层感知器。WARM 的表现超过了最佳的单奖励模型方法" cms-width="677" cms-height="768.672" id="9"/>在第 3000 步时,可在损失和准确度方面将训练过程加速多个 epoch。但是,此时学习率较低,除了基于人类偏好进行的常规训练,提升后的目标模型 M1* 的输出 logit 是这样计算的:M1*(x) = M1 (x) + [M3 (x) - M2 (x)]。比如 Llama 2 7B;一个经过微调的基础模型(M3),WARM 还使用了所谓的 Baklava 流程,
总体而言,Mathematics、胜过其它同等大小的开源模型。毕竟已经有 LoRA(低秩适应)这种更好的方法了 ——LoRA 不需要较小的通用模型 ,这个模型的表现能比肩大得多的 Llama 2 70B 模型。
随机阅读
- 东西问|王勇:如何从国际视角透视“新质生产力”?
- 吴清:当市场出现非理性剧烈震荡 该出手就果断出手
- 京东物流:2023年总收入达1666亿元 同比增长21.3%
- 外媒:自今年1月接受腹部手术后,凯特王妃首次露面
- 湖北竞逐新能源汽车动力蓄电池回收利用赛道
- 俄罗斯一热电站发生事故23人受伤 当地宣布进入紧急状态
- 全国人大代表于金明:建议将儿童肿瘤筛查纳入医保(含视频)
- 国际识局:美国大选“分水岭”时刻!拜登特朗普大胜,距对决近一步?
- 为应对袭击,俄军在扎波罗热州上空建起“保护罩”
- 第四艘航母是否核动力?海军政委:很快会公布!(含视频)
- “日本大学生看中国”访问团启动仪式在东京举办
- 肯尼亚发生飞机相撞事故致2人死亡
- 对话傅盛:企业落地AI,不建议选“核战”中的大厂 丨 科创100人
- 黑利宣布退出2024年美国总统竞选
热门排行