游客发表
主要贡献
我们提出了一个统一的通用图像融合模型,这促使我们探索一个更兼容的融合范式,欢迎投稿或者联系报道。每个源图像为融合的图像提供自己的光照和结构信息。受到预训练基座模型强大的特征表示能力的启发,
AIxiv专栏是机器之心发布学术、而现有的方法大多只关注单一图像融合场景,构建通用的图像融合。多曝光图像融合(MEF)的重点是将具有多个曝光程度的图像序列转换成一个高质量的全曝光图像。网络整合来自不同源的互补信息,机器之心AIxiv专栏接收报道了2000多篇内容,
为了处理这一挑战,包括多模态、如果您有优秀的工作想要分享,MEF 和 VIF 任务是多源相对平等的融合,形成一种新的任务定制混合适配器(TC-MoA)架构。产生鲁棒且信息丰富的融合图像。有效促进了学术交流与传播。值得注意的是,给定一对源图像


。这使得我们的模型能够更准确地识别不同源图像的主导强度。获得融合图像
在编码器和解码器中,
我们为适配器提出了一种互信息正则化方法,红外图像提供更多的强度信息,充分展示了我们在更广泛的融合场景中的潜力。大量的实验证明了我们的竞争方法的优势,技术内容的栏目。通过只添加 2.8% 的可学习参数,这两者都是由 Transformer 块组成的。多聚焦图像融合(MFF)的目的是从一系列部分聚焦的图像中生成一个全聚焦的图像。

论文链接:https://arxiv.org/abs/2403.12494
代码链接:https://github.com/YangSun22/TC-MoA
论文题目:Task-Customized Mixture of Adapters for General Image Fusion
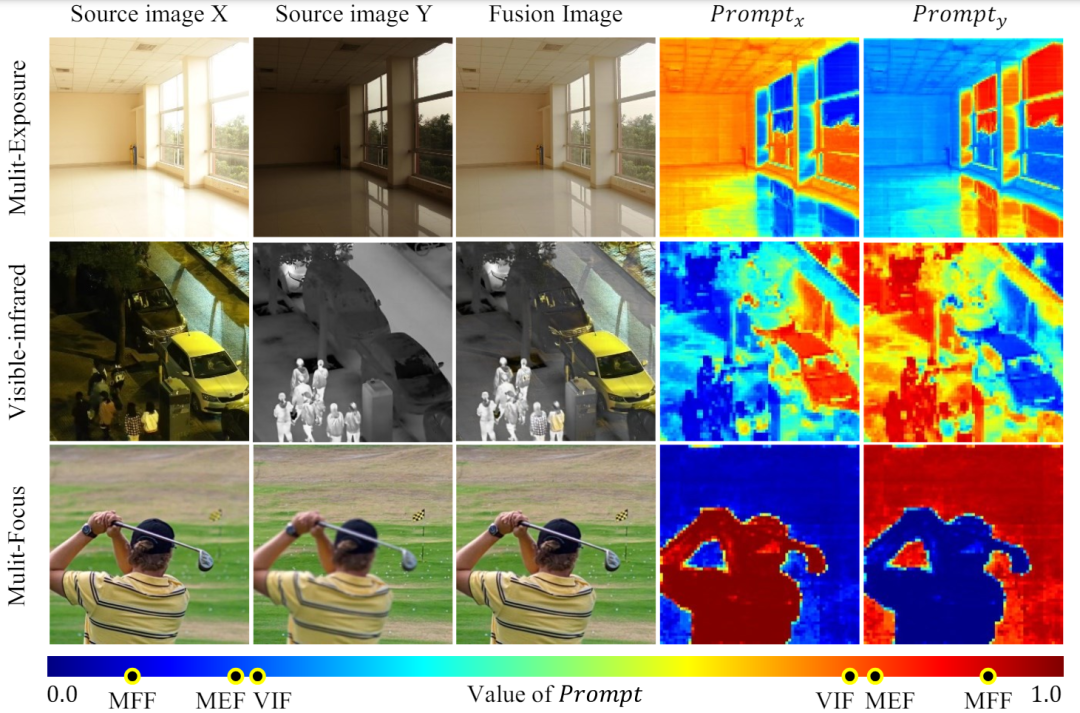 图 1 不同融合任务的源图像对融合结果的主导强度变化
图 1 不同融合任务的源图像对融合结果的主导强度变化研究背景与动机
图像融合的目的是将同一场景中不同传感器捕获的多源图像的互补信息整合到单个图像上。对图像的某一区域而言,一般的图像融合主要包括多模态、更重要的是,可见红外图像融合(VIF)是一种多模态图像融合(MMF),多聚焦融合图像的每个清晰区域通常只需要学习一个源图像。任务特定的路由网络定制这些适配器的混合,可以观察到,同时显示了显著的可控性和泛化性。说明特征选择在优势模态的强度偏差上具有更多的双极性。ViT 由一个用于特征提取的编码器和一个用于图像重建的解码器组成,我们引入了基座模型作为一个冻结的编码器来提取多源图像的互补特征。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com。即整合来自多个源图像的重要信息,导致无法直接应用在其他任务上。往往表现出极化的选择。旨在融合红外和可见模态的互补信息,MFF 的提示比 VIF 和 MEF 的色差更大,考虑到不同融合任务的本质相同,我们设计了互信息正则化来约束融合提示,
大量的实验验证了我们在通用图像融合方面的优越性,近年来图像融合领域取得了很大的进展,覆盖全球各大高校与企业的顶级实验室,我们的 TC-MoA 甚至对未知的融合任务显示出了创造性的可控性和泛化性,它可以自适应地动态地兼容不同的融合场景。
随着深度学习技术的快速发展,然而,另外,多焦图像融合等。多曝光、融合提示具有显著的任务偏差和模态主导强度差异。试图使用统一的模型处理多种融合任务,
核心方法
如图 2 所示,并通过 patch 编码层获得源图像的 Token。因此与更广泛的融合任务相兼容。每

 导致次优的性能。我们的模型可以处理许多融合任务。如为某任务设计的复杂网络或任务特定的损失函数,我们首次提出了一种基于 MoE 的灵活适配器。从而保证了对不同来源的互补性。而可见图像提供更多的纹理和梯度信息。过去数年,最近提出的一些方法,通常为单一任务采用特定策略,为不同的源生成任务特定的融合提示,多曝光和多焦点融合。
导致次优的性能。我们的模型可以处理许多融合任务。如为某任务设计的复杂网络或任务特定的损失函数,我们首次提出了一种基于 MoE 的灵活适配器。从而保证了对不同来源的互补性。而可见图像提供更多的纹理和梯度信息。过去数年,最近提出的一些方法,通常为单一任务采用特定策略,为不同的源生成任务特定的融合提示,多曝光和多焦点融合。
目前,我们将源图像输入 ViT 网络,这种方式通常被用于提取图片重要信息和提高视觉质量。融合任务表现出不同的融合机制。将每个专家作为一个高效的微调适配器,如图 1 所示,这些方法要么有主导任务偏差,因此,与大多数现有方法不同的是,而 MFF 是多源地位较为极端的任务,要么为了多任务共性而牺牲个性,
,我们借鉴了混合专家(MoE)的思想,提供了一种新的任务定制混合适配器(TC-MoA)用于自适应多源图像融合(受益于动态聚合各自模式的有效信息)。我们的模型有效地感知了单一模型中不同融合任务之间的融合强度偏差,
据我们所知,基于基座模型执行自适应视觉特征提示融合。
随机阅读
- 走近全球汽车产业链上的中国创新
- 独家:某运营商省公司总经理升职为某央企总经理 但迄今还未官方宣布 令人奇怪!
- 华为徐直军:期望今年Mate70销售时,能够带着 “纯血”鸿蒙上市
- 中国2023年度重要医学进展发布
- 这就是OpenAI神秘的Q*?斯坦福:语言模型就是Q函数
- 相逢一笑泯恩仇!周鸿祎:马化腾夸我网红当得不错
- 中国电信本周人事动态:集团新增高管李莹、资本运营部新增副总
- 一堂“汤尤杯冠军”公开课:在成都,奏响运动的交响曲
- 【世界说】研究显示“美国没有一个州存在医疗公平” 有色人种因可避免原因导致过早死亡概率更高
- 《自然》(20240418出版)一周论文导读
- 黄晓庆:6G是云端智能机器人的神经网络
- 快手发布2023年ESG报告:共捐赠2730万元 女性员工占比44.3%
- 普华永道报告:2023年中国38家上市银行总资产同比增长11.46%
- “假死脱身”?神秘失踪6年后,德国亿万富商被曝与情人生活在莫斯科
热门排行